How Predictive Maintenance Works: Data, Sensors, AI, ROI
Learn how predictive maintenance works, from data & sensors to AI and ROI. Implement a system to cut costs, prevent breakdowns, and boost uptime.
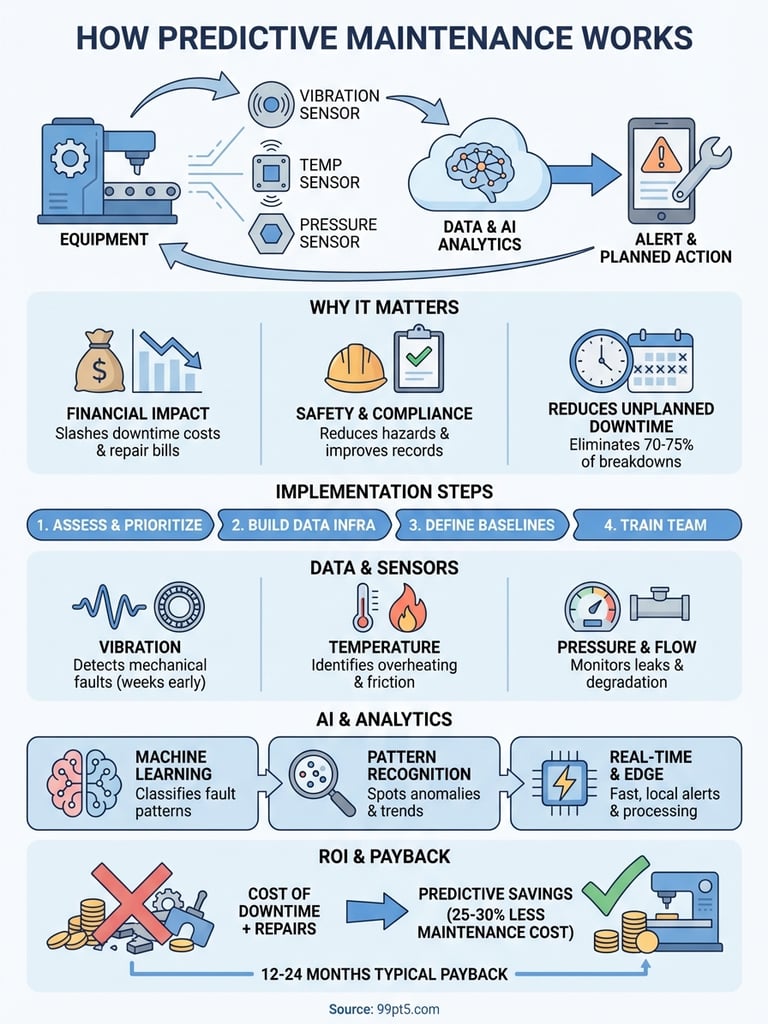
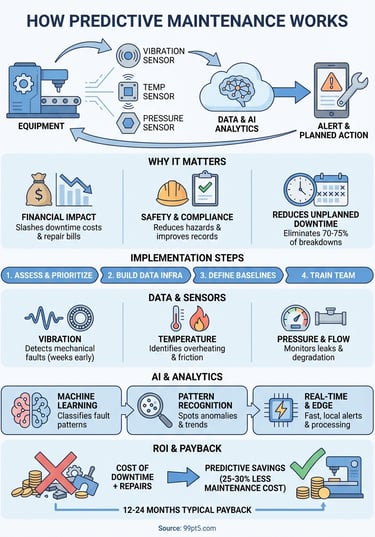
Predictive maintenance monitors equipment health through sensors and data analytics to catch problems before they cause breakdowns. Instead of fixing machines when they fail or maintaining them on a fixed schedule, you get alerts when something actually needs attention. Sensors track conditions like temperature, vibration, and pressure. Machine learning algorithms analyze this data to spot patterns that signal upcoming failures. When the system detects an anomaly, it triggers a maintenance work order so your team can address the issue during planned downtime rather than scrambling during an emergency shutdown.
This guide walks you through the practical mechanics of predictive maintenance. You'll learn what sensors and data sources matter most, how to implement a program from scratch, and what AI technologies power the predictions. We'll break down the costs and show you how to calculate your return on investment. By the end, you'll understand exactly how predictive maintenance works and whether it makes financial sense for your operations. The focus stays on actionable information you can use to make better equipment maintenance decisions.
Why predictive maintenance matters
Your equipment downtime costs you far more than just repair bills. Unplanned failures disrupt production schedules, force you to pay overtime labor rates, and create supply chain bottlenecks that ripple through your entire operation. Traditional maintenance approaches leave you choosing between two bad options: wait for breakdowns or perform unnecessary preventive work based on calendar schedules rather than actual equipment condition. Understanding how predictive maintenance works gives you a third path that eliminates most unplanned downtime while cutting your maintenance budget by up to 30%.
Financial impact on operations
Equipment failures cost manufacturers an average of $260,000 per hour according to industry studies. You absorb these losses through lost production, emergency repair costs, rush shipping fees for replacement parts, and potential penalty payments for missed delivery commitments. Predictive maintenance slashes these costs by catching problems days or weeks before they cause shutdowns. Your team schedules repairs during planned maintenance windows when parts are already in stock and technicians are available at regular rates rather than emergency overtime pay.
Predictive maintenance reduces maintenance costs by 25-30% compared to preventive schedules and eliminates 70-75% of equipment breakdowns.
Safety and regulatory benefits
Equipment failures put your workers at risk. Catastrophic failures like bearing seizures, pressure vessel ruptures, or motor explosions create immediate physical hazards. Predictive systems monitor safety-critical equipment continuously and alert you when operating parameters drift toward dangerous zones. You also maintain better compliance records for regulatory audits because sensor data provides documented evidence of equipment health monitoring and timely maintenance interventions.
How to implement predictive maintenance
You build a predictive maintenance program through a systematic rollout that starts with your most critical equipment. Implementation typically takes three to six months from initial planning to full operation, though you can start monitoring your first assets within weeks. The key to success lies in starting small with high-value equipment where downtime costs justify the sensor investment, then expanding coverage as you prove ROI and build team expertise. This measured approach lets you learn how predictive maintenance works in your specific environment before committing to facility-wide deployment.
Assess your equipment and prioritize assets
Identify which machines warrant predictive monitoring by calculating their failure costs and downtime impact. Your boilers, compressors, pumps, and production line motors usually top the priority list because their failures halt entire operations. Create a risk matrix that ranks each asset by criticality (how essential it is) and failure probability (how often it breaks down). Assets that score high on both dimensions become your Phase 1 implementation targets. You also want to consider maintenance costs under your current approach because predictive systems deliver the biggest savings on equipment that currently requires frequent interventions.
Build your data collection infrastructure
Install IoT sensors on your priority assets according to the monitoring requirements for each machine type. Rotating equipment needs vibration sensors, thermal equipment requires temperature monitoring, and pressurized systems demand pressure transducers. Connect these sensors to a central data platform through either wired networks or wireless protocols like LoRaWAN or cellular connectivity. Your data platform should integrate with your existing CMMS (Computerized Maintenance Management System) so alerts automatically generate work orders rather than requiring manual data review and action.
Companies that integrate predictive maintenance alerts with their CMMS reduce response times by 35% compared to manual alert monitoring processes.
Define baselines and configure alert thresholds
Establish normal operating parameters for each monitored asset by collecting at least two weeks of data during healthy operation. These baselines tell your system what "good" looks like so it can detect deviations. Set your alert thresholds at levels that catch developing problems early without triggering false alarms that waste technician time. You might configure a warning level at 10% deviation from baseline and a critical alert at 25% deviation, adjusting these values based on your experience with each asset type.
Train your team and refine processes
Prepare your maintenance technicians to interpret predictive alerts and verify sensor readings against their operational knowledge. They need to understand that alerts indicate potential problems requiring inspection, not automatic part replacements. Document your response procedures for different alert types so any team member can handle them consistently. You should also schedule monthly reviews of your alert accuracy during the first year, adjusting thresholds to reduce false positives while ensuring you catch real problems before they cause failures.
What data and sensors you need
Your predictive maintenance system requires specific sensors matched to each equipment type and failure mode you want to detect. Sensor selection determines what problems you can catch and how early you spot them, so you need to understand which measurements matter most for your assets. Data quality matters more than data quantity because a few accurate readings beat dozens of unreliable signals that trigger false alarms. Understanding how predictive maintenance works starts with knowing what physical conditions indicate equipment health and choosing the right sensors to track those parameters continuously.
Vibration sensors for rotating equipment
Vibration analysis catches the widest range of mechanical problems in motors, pumps, compressors, and conveyor systems. You install accelerometers or velocity sensors near bearings and coupling points to detect imbalance, misalignment, bearing wear, and looseness. Frequency analysis of vibration data reveals specific fault signatures like bearing race defects at characteristic frequencies or gear tooth problems that show up as sidebands in the spectrum. Most rotating equipment above 600 RPM benefits from vibration monitoring because these sensors detect problems weeks before you hear unusual noises or feel excessive heat.
Vibration sensors detect bearing failures an average of 30 days before equipment breakdown, giving you ample time to schedule repairs during planned maintenance windows.
Temperature and thermal monitoring
Thermal imaging cameras and temperature sensors identify overheating in electrical systems, mechanical components, and process equipment. You mount infrared sensors on motor housings, bearing surfaces, electrical panels, and drive components to catch rising temperatures that signal friction, electrical resistance, or cooling system failures. Temperature trends often provide earlier warnings than absolute readings because a 10-degree increase over two weeks matters more than hitting a specific threshold value. Your thermal monitoring should cover both equipment surfaces and internal process temperatures to catch problems in both mechanical components and the systems they operate.
Pressure and flow measurements
Pressure transducers monitor pumps, compressors, hydraulic systems, and pressurized vessels to detect leaks, blockages, and component degradation. You need continuous pressure readings rather than occasional gauge checks because gradual pressure drops signal seal wear or filter clogging before they cause system failures. Flow meters track fluid movement through pipes and detect changes in pump efficiency, valve operation, or line restrictions. These measurements prove particularly valuable in process equipment where maintaining specific pressures and flow rates determines product quality and equipment longevity.
AI and analytics behind predictive maintenance
The software layer transforms raw sensor data into actionable maintenance insights through machine learning algorithms and advanced analytics. Your predictive system continuously processes thousands of data points per second, comparing current readings against historical patterns to identify anomalies that human observers would miss. Artificial intelligence learns from every failure event, refining its predictions to catch problems earlier and reduce false alerts over time. This is how predictive maintenance works at the software level: algorithms trained on your equipment's operational history spot subtle changes that precede failures, giving you precise warnings instead of vague "something might be wrong" alerts.
Machine learning algorithms for fault detection
Supervised learning models form the foundation of most predictive systems because they classify sensor patterns into specific fault types. You train these algorithms using historical data where you know what failed and what sensor readings preceded each failure. Neural networks excel at finding complex relationships between multiple sensor inputs, while decision trees provide more transparent logic that technicians can understand and trust. Your system might use random forest algorithms that combine multiple decision trees to improve accuracy, or gradient boosting methods that iteratively refine predictions based on previous errors.
Pattern recognition and anomaly detection
Unsupervised learning catches problems you have never seen before by identifying deviations from normal operation patterns. These algorithms establish a baseline of healthy equipment behavior without requiring labeled failure examples. Clustering techniques group similar operating conditions together, then flag readings that fall outside established clusters as potential problems. Your system also employs time-series analysis to detect gradual degradation trends that develop over weeks or months rather than sudden changes.
Machine learning models trained on facility-specific data achieve 85-95% accuracy in predicting equipment failures 7-14 days before breakdown.
Real-time processing and edge computing
Edge devices process critical data locally at the equipment level rather than sending everything to the cloud, enabling sub-second response times for safety-critical alerts. You deploy lightweight algorithms on industrial computers or smart sensors that filter noise and compress data before transmission. Cloud platforms handle the heavy computational work like model training and long-term trend analysis, while edge devices execute the trained models for real-time monitoring. This hybrid architecture balances processing speed with analytical power, giving you both immediate fault detection and sophisticated pattern analysis.
Calculating ROI and payback time
Your predictive maintenance investment pays back through reduced downtime costs, lower repair expenses, and extended equipment life. Calculating ROI requires tracking specific cost metrics before and after implementation to quantify real savings rather than relying on industry averages. Payback periods typically range from 12 to 24 months for properly implemented systems, though critical equipment with high failure costs can justify the investment in under six months. The calculation process reveals whether predictive maintenance makes financial sense for your specific operation and helps you prioritize which assets to monitor first.
Key cost factors to measure
Track your baseline costs for each monitored asset by documenting unplanned downtime hours, emergency repair expenses, replacement part costs, and production losses over the past 12 months. You need these numbers to calculate your savings accurately after implementation. Include hidden costs like overtime labor, expedited shipping fees, quality issues from equipment degradation, and the ripple effects on downstream processes when a machine fails. Most facilities underestimate their true failure costs by 40% when they only count direct repair bills without considering operational impacts.
Expected savings and timeline
Predictive systems reduce maintenance costs by 25-30% while cutting unplanned downtime by 35-45% based on data from the US Department of Energy. Your ROI calculation should divide total implementation costs (sensors, software, training) by annual savings to determine payback time. Conservative projections assume you eliminate only 50% of unplanned failures in year one while learning how predictive maintenance works, then achieve 70-75% elimination by year two as your team gains experience.
Facilities with properly implemented predictive maintenance achieve ROI of 10:1 over five years, with initial investments paying back within 18 months on average.
Build a detailed business case that accounts for ongoing subscription costs, sensor maintenance, and staff time while documenting both hard savings (reduced repair costs) and soft benefits (improved safety, regulatory compliance). Your finance team needs these projections to approve the capital investment and track actual performance against expectations.
Wrapping up
You now understand how predictive maintenance works from data collection through AI analysis to actionable alerts. Implementation success depends on starting with your highest-value equipment, choosing sensors matched to specific failure modes, and training your team to act on system insights rather than calendar schedules. Your ROI calculation should account for both direct savings from reduced repairs and indirect benefits like improved safety and production reliability. Most facilities achieve payback within 18 months while building operational expertise that compounds over time.
The same principles apply across industries whether you operate manufacturing lines, process equipment, or specialized systems. Biogas processing operations and other continuous systems benefit particularly from predictive monitoring because preventing costly shutdowns maintains guaranteed output levels and keeps revenue streams flowing. Start your program with critical assets and expand coverage as you prove value through documented cost reductions and uptime improvements.